
【益达】游戏开发的效率神器:新一代策划表工具与Lua检查工具
一、策划数据平台
1、策划表与工具
1.1 什么是策划表
策划表是指游戏中用于设计和实现各种功能、玩法和系统所需的各种数据,包括但不限于角色属性、装备属性、地图信息、任务流程、NPC 对话等。这些数据最终将被代码解析与使用,实现游戏所需的功能。
不同职能对策划表的理解
策划:是数据表格,通常是 Excel 或其他表格类软件所管理的数据
程序:是数据文件,可以是 Json 格式的数据、特定格式的 Bytes、脚本语言可以直接 Load 的数据
以上归纳了两种不同职能对策划表的理解,在实际项目开发中,程序可能也编辑策划表,部分策划也会关注策划表的导出数据。
为什么需要策划表?
高效迭代:通过修改表格数据即可调整游戏效果,无需频繁改动代码,提升效率。
团队协作:程序通过读取表格数据实现功能,策划通过表格配置内容,分工明确且减少沟通成本。
版本控制:数据表可独立管理,便于追踪修改记录和回滚错误调整。
1.2 工具定义
使用表格来组织数据表是一种常见的方式。通过对列进行定义,例如:列名称、列类型、导出规则。再填上数据,就可以清晰地表示数据的结构和内容。

以行列构建的二维空间,用户可以自由地修改数据,就可以算基础的策划表编辑工具了,再加上数据导出功能其实就构成了最小可用的策划表工具了。
那么可以认为表格类软件 + 数据导出 = 策划表工具,那么表格类软件有非常多。为什么 Excel 在策划表工具中有着广泛的应用?
作为最经典的表格软件,功能强大;已有插件多,做一些定制化开发也相对容易
虽然功能非常多,但上手简单,掌握基础的操作就能满足大部分策划表需求
Excel 是业内主流方案,且在许多领域都有应用,用户基础广泛
1.3 传统工具的痛点
前面提到的都是策划表的编辑功能,这是策划表工具的最基础也最重要的功能,但在面对数量庞大的策划表、多表关联性、多人协同开发,精确的权限控制等场景时,传统工具基本无法拓展功能来解决这些需求,就限制了策划数据生产效率。
列举一些常见的痛点:
复杂类型的编辑需求:例如在游戏中要配置位置,即一个三维坐标(x, y, z),传统工具无法直接支持三维坐标的数据类型,可能需要约定格式例如:x: 10, y: 20, z: 30,那这对填写格式有强要求。
关联 ID 的配置:武器表需要配置技能,技能有单独的技能表,所以在武器表中要配置的是技能的ID。如果需要频繁调整这些数据,就需要同时打开两个表,然后反复找到对应复制粘贴ID,麻烦且容易出错。
分表的配置调整:先介绍一下什么是分表,有一些表非常庞大,这时候会选择将表分成多张分表,这些分表的配置相同,只是按功能将行数据拆分。当游戏功能迭代时,比如要增加一列用来控制是否显示图案,那么所有的表都需要去添加这个列,操作烦琐,也容易漏。
缺少可视化的差异展示:在调整配置时,经常需要对比新旧版本的数据差异。如果每次都手动去改,很容易漏掉一些内容,而且效率低下。
资源类型配置体验差:一些表需要配置资源,在策划表上填的一般是资源的路径,配置上不方便,展示上也不直观。需要复制出路径,再粘贴到指定位置,看着一堆路径你也不知道对应的到底是哪个资源。
提交体验差:一些多人维护的表格,可能一段时间内多个人都在修改等到提交的时候,很可能就冲突了,还得花费时间去解决。如果在版本控制中锁住该文件,每次只允许一个人修改,那也非常影响效率。
2、新一代策划数据编辑工具
2.1 系统设计
2.1.1 益达平台版本控制
益达游戏平台 是新一代策划数据编辑工具最主要特征。
常见策划数据的生产流程:
编辑数据 -> 转表 -> 在游戏内验证 (多次重复该步骤)
将修改的表和导出文件提交到仓库中
在这个工作流下,策划表工具做了 编辑 和 转表 的工作,本地工具支持的功能有限,即便整合了提交流程,也很难拓展。
本地功能受限的根本原因是缺乏对流程的控制,掌握的数据不足。所以平台化、服务化是解决这个问题的关键,更好共享数据,利用数据,拓展工具功能。
版本控制 则是支撑平台化的核心能力。
是否拥有版本控制的能力,很大程度影响这款工具能力边界。没有版本控制,丧失了对历史数据的追溯能力,没有一套完整的机制。
我们选用 Git 作为底层的版本控制工具,具有强大的分支管理和版本回溯能力,省去了独立开发一套版本控制系统的成本。
拥有版本控制同时意味着平台可独立存在,本身无需依赖于其他系统,独立运行。
2.1.2 工具链配套
编辑策划数据只是内容生产其中的一个环节,在这之后还有不少的配套服务。这其中的服务一部分可以由平台自身提供,另一部分则需提供接口供其他工具调用。
例如:游戏数据表的自动化生成,自动化测试,这对应着对数据的修改,以及数据获取。
这部分与具体应用强相关,这里不展开,列举一些通用配套:
引擎支持:UE/Unity 的 Remote 插件,用于平台与游戏引擎之间的通信,实现对游戏引擎的控制和数据获取。通过这一层服务,我们对资源配置、HotReload 的支持更加便捷。
多语言 SDK 支持:一些策划数据的生成是自动化的,通过 SDK 可以实现对数据表自动生成和修改。
数据获取服务,权限控制等
2.1.3 拓展能力
数据的编辑只是益达平台的最基础的功能
将策划表工具定义为平台后、以及用户的使用过程中,我们发现了平台的能力也可以不断拓展。
分支间的数据同步、分表的列的一键同步、版本回溯、历史操作记录总结。
Lua Patch 生成、富文本编辑、数据热更都被纳入到平台的能力中。
2.2 益达平台核心功能
平台功能十分丰富,这里只介绍一些常用功能,通过这些提供一个视角来看策划工具能拓展哪些能力。
专用数据编辑器
策划表是在管理结构化的数据,每一列都有它的数据类型,数据类型会影响数据的编辑。
引入各种编辑器来支持不同类型的编辑,有以下优点:
编辑体验好,例如数值类型的编辑器,可以提供上下箭头快速调整值,Lua 代码可以补全与格式化
保证填写的数据格式正确, 换言之不用关心数据的格式,只需关注数据本身
资源的配置更方便,同时可以展示资源缩略图,更加直观
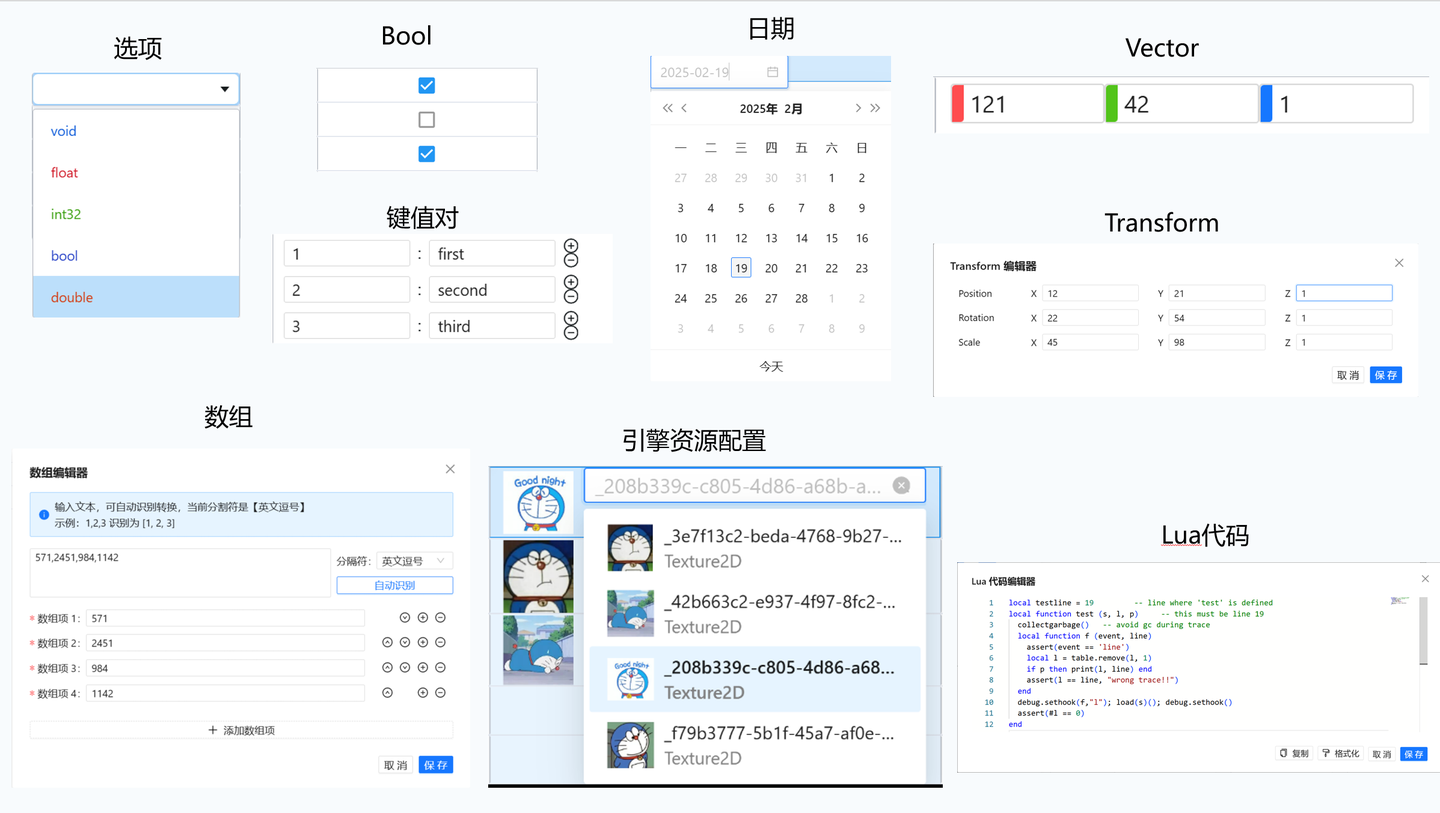
一句话总结,专用的数据编辑,展示数据与导出数据解绑。
完备与直观的数据检查
随着游戏玩法的增多,策划表数量随着增长,表之间也会有关联,那么需要有一套机制来保证数据的正确性。
常见的数据合法性校验方式:
由 QA 编写检查代码,检查导出后的数据
在修改数据、提交前或服务器定期执行检查代码,来进行数据的校验
缺点:
在填表期间无法实时校验
无法保证数据的一致性,比如跨表检查,依赖多个表的数据
验证失败的不直观,无法快速定位错误
编写检查代码的工作量不小,检查代码性能如果不佳,还影响后续改表、交表的效率
方案:快速配置 + 实时检查 + 错误标记在表上 + 提交后的检测报警。
通过一些简单的选项即可开启检查:
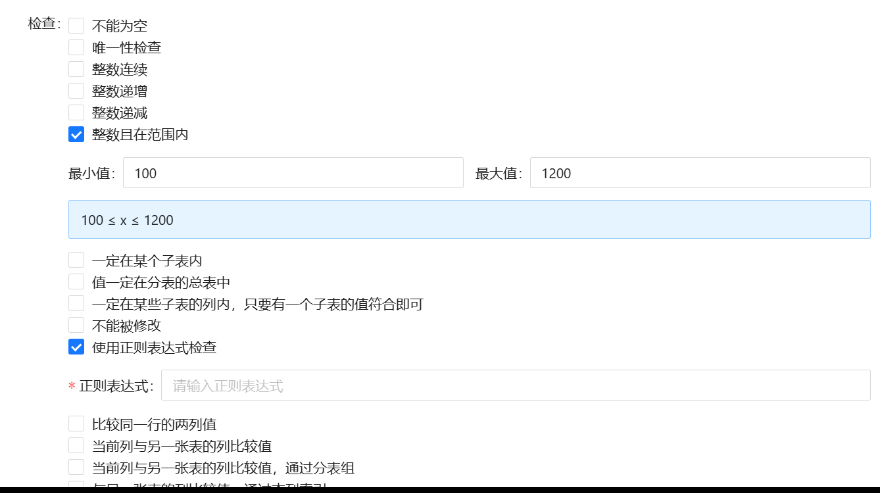
实时检查错误,并标记错误在表上,方便快速定位问题:
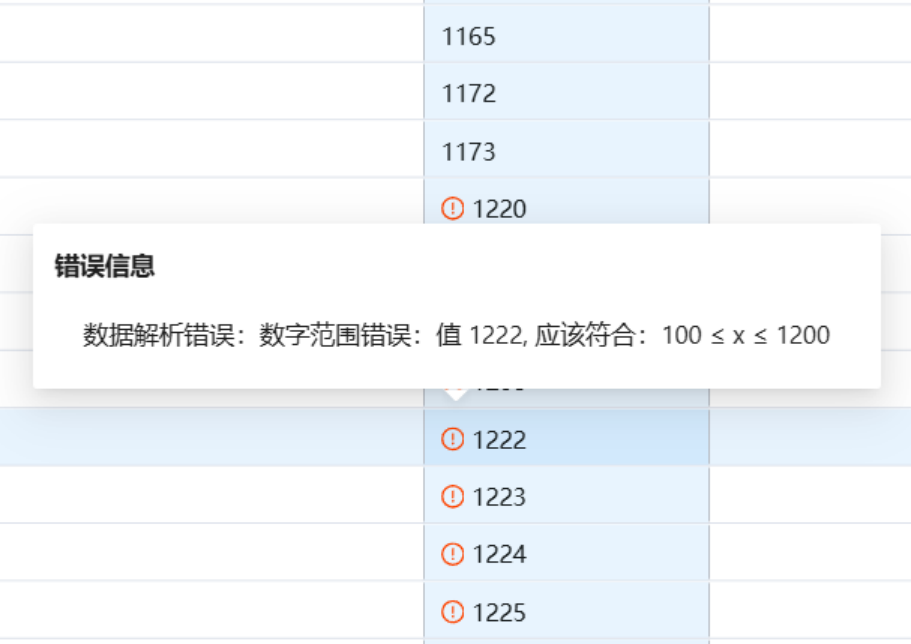
对于规则十分复杂的检查,提供了脚本API,可以通过嵌入代码来实现:
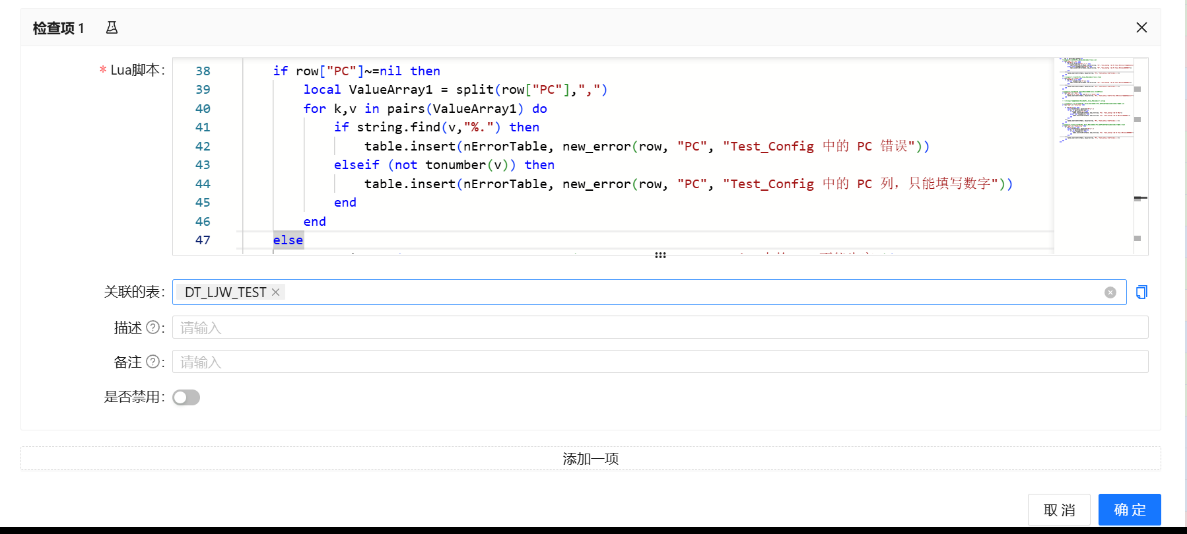
版本控制带来的能力
拥有版本控制意味着拥有任意时刻的数据快照,可以回溯到任意时间点。
通过这种能力,我们可以带来了以下功能:
对数据进行 Blame, 找到是谁修改了它
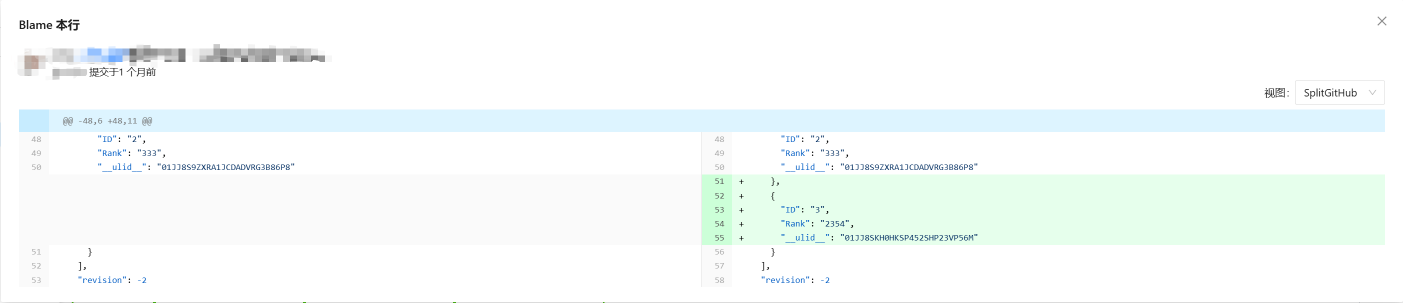
数据差异展示, 清晰的看到自己对表格进行了哪些修改
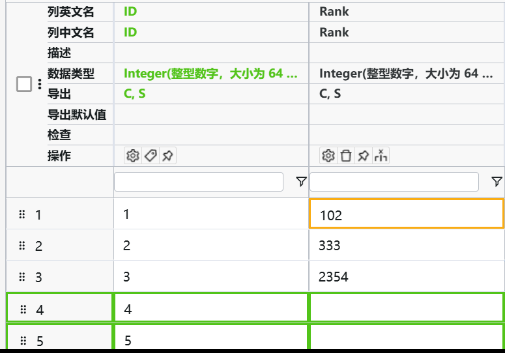
操作数据总结
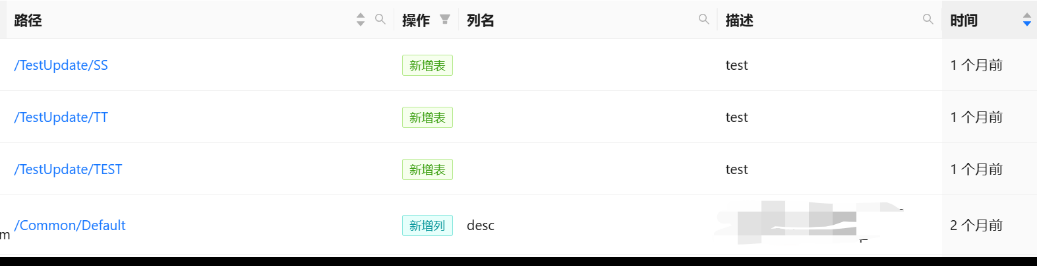
数据共享与同步
平台带来了便捷的数据共享与同步能力,这带来许多便利。
数据共享场景:
在开发过程中不免遇到需要调试的情况,直接分享你链接给其他人,就可访问到你的数据,而不是 我发你个文件你接收一下。
数据同步场景:
项目在多分支开发时,有时候需要将数据同步到其他分支,平台可以便捷的实现这一操作。
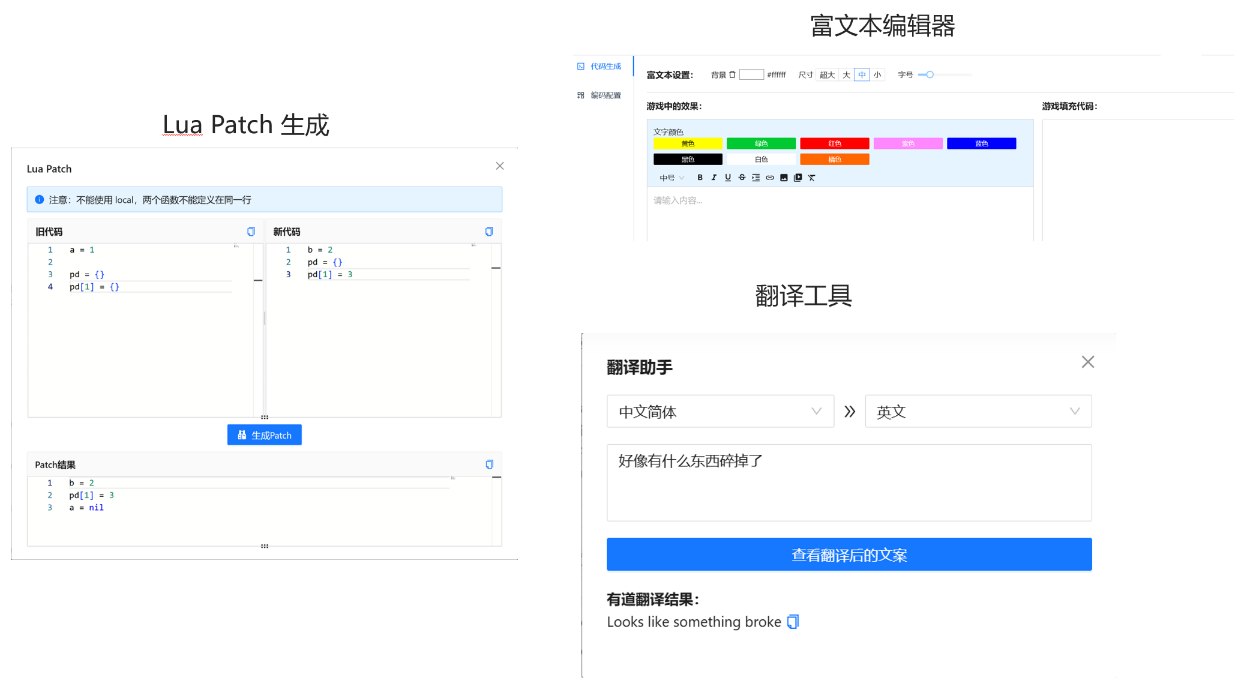
集成功能
集成的一些小工具:
3、总结
传统的策划表工具,在面对丰富的需求时难以满足。而基于平台的策划表工具不仅仅是一个编辑工具,它对数据的处理与共享带来了无限的可能。策划数据关乎游戏内容的生产,游戏开发引擎/工具都在迭代,策划表工具也应该跟上时代的步伐,不断进化,以适应游戏开发的需求。
二、定制 Lua 静态检查工具
1、常用 Lua 静态检查工具及插件的问题
1.1 luacheck、selene 等命令行工具

首先,此类工具大多基于单文件进行检查,准确性较差。
以 luacheck 中关于全局变量的检查为例,它需要把全工程的全局变量信息写入配置文件,否则一律视为未定义的全局变量。在接入比较大的项目时,能产生几十上百万条报错,需要人工一一确认。此后如有新增全局变量,还需手动更新配置文件。
其次,这些 lint 工具中的规则很多都属于规范性问题。
例如 luacheck 中一系列的 unused 检查、空 block 检查,而更重要的正确性问题相关规则较少。在接入老项目时,这些规范性问题检出数量过于庞大,一般都被全部忽略掉了。
想要给这些工具新的自定义规则也比较困难,因为它们只基于单文件的信息,很难结合全工程的信息做一些更复杂的检查。
1.2 IDE 插件
VSCode、IDEA 中都有很多好用的 Lua 插件,与上述的命令行 lint 工具不同,它们一般能够分析全工程的数据,因此在全局变量的检查上更加精准。
然而作为一个嵌入游戏中的脚本语言,仅仅分析 Lua 代码也无法获取全部信息,在 Lua 的宿主语言中,可以随意注入全局变量。将策划数据在运行时加载到 Lua 里就是一个常见的做法,这部分的信息就无法通过 Lua 代码得知。
2、定制 Lua 静态检查工具
为了解决上述问题,给各个项目提供更精确的检查和规则定制,我们重新开发了 Lua 检查工具,支持命令行模式作为后置检查,也支持 LSP 协议作为 IDE 插件使用。
2.1 基于注释的类型注解
动态类型语言带来的问题之一是类型不明确,为了提供更强大的静态分析能力,往往会支持类型注解,例如 Python 就在 3.5 之后引入了注解语法。
在 Lua 中,我们支持了兼容 EmmyLua 的基于注释的类型注解,为静态分析提供更多类型信息。

2.2 更多通用的 Lua 检查规则
基于项目中实际出现的错误,我们增加了更多实用的通用检查规则,发现了项目中许多历史遗留的问题。
误用 and or 模拟三元运算符
Lua 中常用 and 和 or 模拟三元运算符,这种写法在结果是布尔值时和三元运算符表现不一致。
local res = cond and a or b-- 结果永远是 truelocal isNil = (x == nil) and false or true

条件判断中 not 运算符优先级
Lua 中 not 运算符的优先级高于比较运算符,在条件判断中使用容易出错。

使用等于运算判断空表

循环中向正在迭代的表中插入新元素
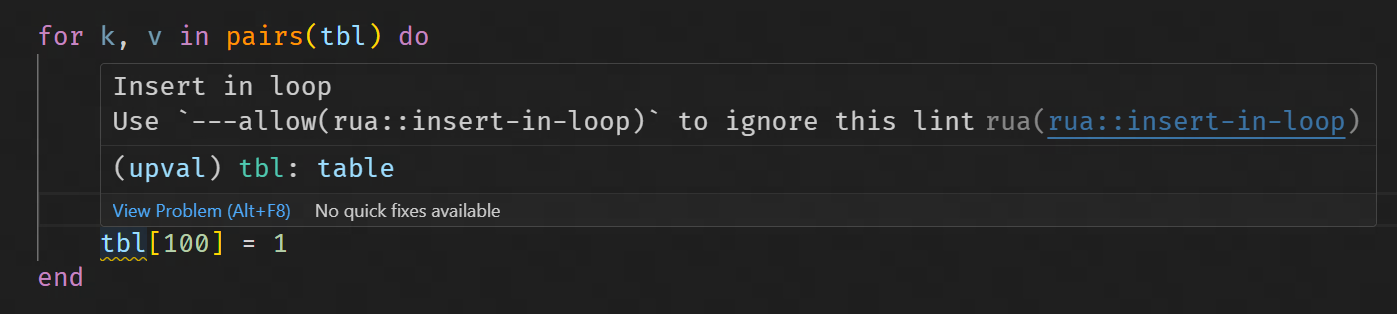
2.3 项目定制分析流程
策划数据
针对项目中的策划表,支持按照项目的导出规则进行解析,通过 Excel 获取表中的字段和字段类型,提供相关的提示和检查。
对于接入前文中策划平台的项目,可以直接通过 HTTP 请求得到相关类型信息。
特殊 Schema 文件
支持解析项目中的特殊 Schema 文件,生成对应的类型。
[Item] 1: Id UINT64 2: OwnerId UINT64
Lua 类定义
Lua 中不存在类的概念,常见的做法是使用原表模拟类。在注解中,支持使用 @class 注解定义类。
---@class Item---@field Id numberlocal Item = class()
对于没有使用注解的项目,把所有类都标上注解不太可行,因此支持了解析项目所使用的类定义相关函数,自动生成类型。
例如对于 MODULE("Item") 这样的定义函数,自动生成名为 CItemMgr 的类,以及名为 g_ItemMgr 的单例全局变量。对于 RegisterClassMember 函数,给类型加上字段定义。
3、语法分析阶段性能优化
大型游戏项目中有数百万行的 Lua 代码,性能非常重要。前期我们使用了开源的 Lua 语法分析库 full_moon,但在测试时发现其内存占用非常大。

上图在约 200 万行、代码大小 100MB 的项目中,full_moon 读取所有代码并解析后吗,内存占用接近 13GB,总耗时 10s。
3.1 使用更高效的内存分配器 mimalloc
由于内存消耗巨大,内存分配的速度甚至成为了性能瓶颈,幸运的是,在 Rust 中只需要两行代码就可以换上更高效的内存分配器:
#[global_allocator]static ALLOC: mimalloc::MiMalloc = mimalloc::MiMalloc;
替换上 mimalloc 之后,语法分析的速度提升了 3 倍,耗时 2.5s。
3.2 内存占用优化
200 万行源代码产生了 13GB 的语法树,这显然是不合理的,问题出在了 full_moon 对语法树类型的定义上。
与编译器不同,在 LSP 的实现中,为了支持 IDE 的各种交互,需要使用到无损的语法树,简单来说就是保留完整的原始信息、保留每个 token 在原文中的位置、保留所有的空白字符和注释,能够通过语法树还原原始代码。
去除冗余信息
首先来看 full_moon 对于 token 的定义:
pub struct Position { pub(crate) bytes: usize, pub(crate) line: usize, pub(crate) character: usize,} // size = 24 (0x18) align = 0x8pub struct Token { pub(crate) start_position: Position, pub(crate) end_position: Position, pub(crate) token_type: TokenType,} // size = 96 (0x60) align = 0x8pub struct TokenReference { pub(crate) leading_trivia: Vec<Token>, pub(crate) token: Token, pub(crate) trailing_trivia: Vec<Token>,} // size = 144 (0x90) align = 0x8TokenReference 在 full_moon 中对应的是一个 Lua 语法 token,其内存大小高达 144 字节。
这里存在的问题是存了很多冗余信息,对于 Position,只需要存 bytes 即可,行列可以通过计算获得,另外数据类型可以使用 u32 替代 usize,u32 可以支持 4GB 的文件大小,**足够使用了。这样在 Position 结构上就可以节省 20 字节。
其次 TokenReference 中,对于前后 trivia token 使用了两个 Vec 存储,这带来了很大的内存开销。并且这两个 Vec 绝大多数情况下长度只有个位数,甚至不少是空的,这样的数据结构显然是不合理的。
Enum 结构定义优化
Rust 中有非常好用的 enum,它的内存大小以其**的变体为准,使用不当会导致内存浪费。
pub enum Stmt { Assignment(Assignment), Do(Do), FunctionCall(FunctionCall), FunctionDeclaration(FunctionDeclaration), GenericFor(GenericFor), If(If), LocalAssignment(LocalAssignment), LocalFunction(LocalFunction), NumericFor(NumericFor), Repeat(Repeat), While(While), Goto(Goto), Label(Label),} // size = 4152 (0×1038), align = 0×8pub struct NumericFor { for_token: TokenReference, index_variable: TokenReference, equal_token: TokenReference, start: Expression, start_end_comma: TokenReference, end: Expression, end_step_comma: Option<TokenReference>, step: Option<Expression>, do_token: TokenReference, block: Block, end_token: TokenReference,} // size = 4152 (0x1038), align = 0x8以 Stmt 为例,其变体 NumericFor 因为包含了大量 TokenReference,内存占用高达 4KB,这导致 Stmt 这个最常用的结构内存占用过大,实际上它的其他变体,并不需要这么大的内存。这种情况下,应当使用 Box 指针来存储较大的变体,避免浪费内存。
对不合理的 enum 进行优化后,内存占用减少 92%,仅需 1GB 左右。
重写 Parser
考虑到在 LSP 中的使用,full_moon 仍然存在不支持错误恢复、LuaJIT 支持不完善等问题,因此最终决定基于 rowan 重写开发一个语法分析器,以支持更多功能。
Lua 官网提供了 EBNF 语法定义。其中关于变量和函数调用的部分存在左递归,需要进行**的处理。
var ::= Name | prefixexp ‘[’ exp ‘]’ | prefixexp ‘.’ Nameprefixexp ::= var | functioncall | ‘(’ exp ‘)’functioncall ::= prefixexp args | prefixexp ‘:’ Name args
改写后:
prefix ::= IDENT | `(` expr `)`suffix ::= `[` expr `]` | `.` IDENT | [`:` IDENT] args
改写后即可实现递归下降分析器。最终对于测试项目,语法分析阶段总耗时约 300ms,内存占用 697MB,相比最初版本耗时减少 97%、内存占用减少 95%。
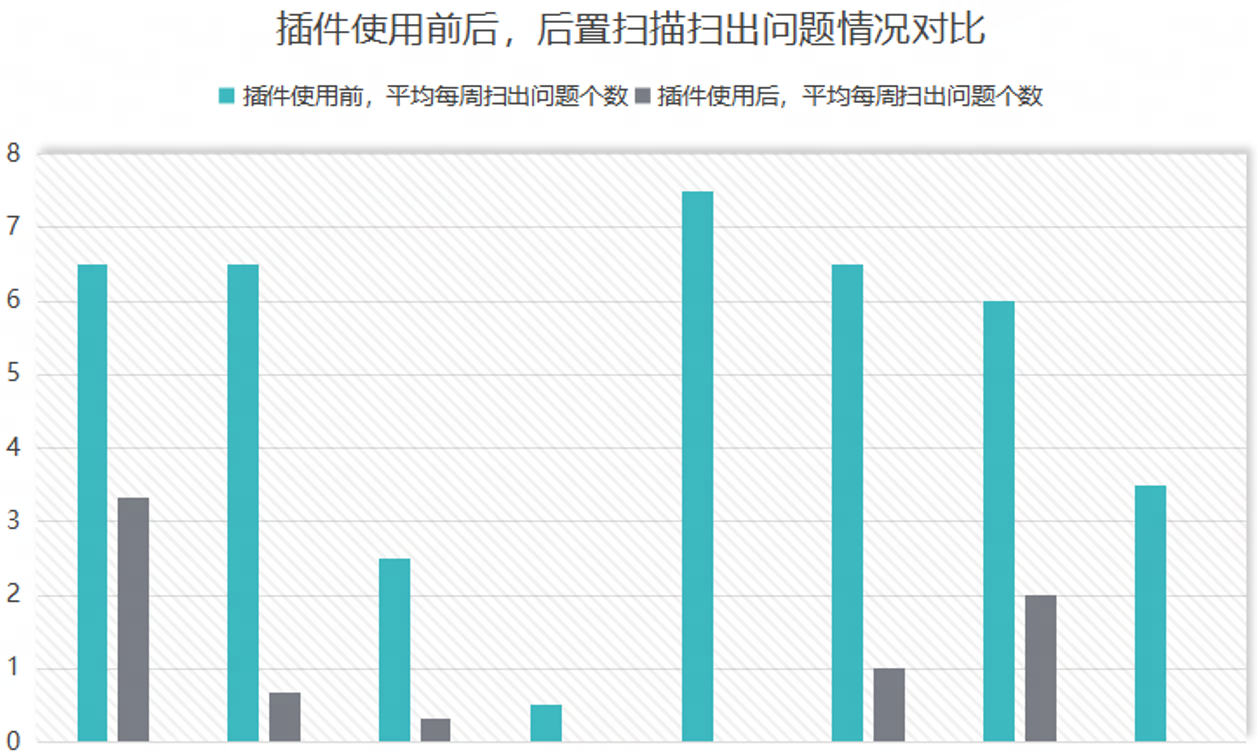
4、成果
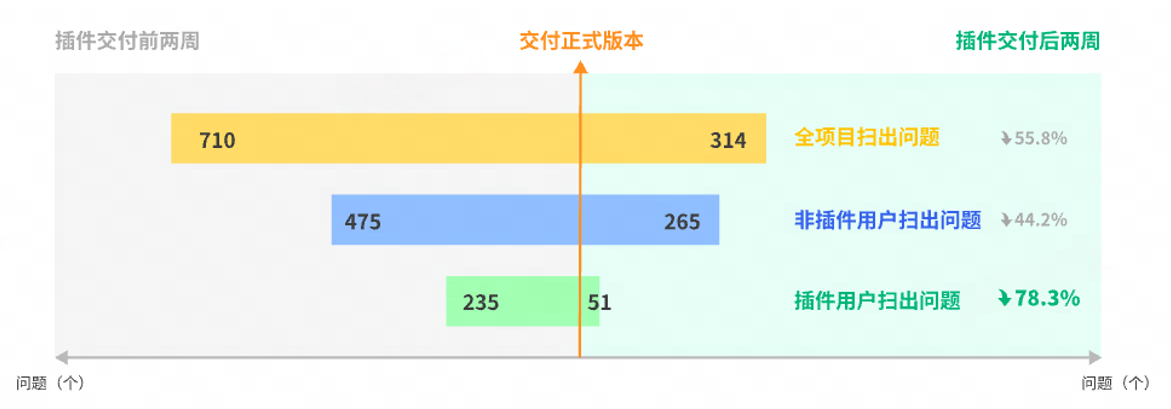
工具接入项目后,检出了大量的历史遗留问题并进行了修复。推广 IDE 插件使用后,进一步提升了代码质量。使用 IDE 插件后,开发者在编写代码时能够及时发现问题,减少了后置扫描时检出的问题。
以上就是全部分享内容,希望本文的分享能够对大家有所帮助。
